In meiner Seminararbeit über Topologiebewusstes, proaktives Ad-Hoc-Routing habe ich mich intensiv mit dem Optimized Link State Routing (OLSR) und dem Hybrid Landmark Routing (Hybrid LANMAR) beschäftigt. Da OLSR ohnehin recht gut dokumentiert und Hybrid LANMAR noch relativ neu ist, stelle ich den Teil zu Hybrid LANMAR online.
Wie der Name bereits andeutet, handelt es sich dabei um ein hybrides Protokoll, es vereint proaktives und reaktives Routing. Genau wie OLSR baut das Hybrid Landmark Routing auf ein bereits existierendes Verfahren auf. Hybrid LANMAR ist eine Optimierung des LANMAR Protokolls. Beide Protokolle nutzen die Annahme, dass es meistens Bewegungen ganzer Gruppen in MANETs gibt. Die eigentliche Optimierung bei Hybrid LANMAR liegt in einer verbesserten Behandlung des Falls, wenn sich einzelne Knoten nicht in einer Gruppe bewegen.
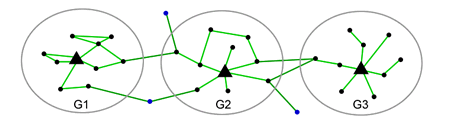
Beispieltopologie Hybrid LANMAR
Wie in der Abbildung dargestellt kann man sich ein MANET mit bewegenden Gruppen (graue Ellipsen) vorstellen. Blaue Punkte sind die Knoten, die sich individuell bewegen und die ich externe Knoten nennen werde. Die grünen Linien sind die Verbindungen zwischen den Knoten. Ein schwarzes Dreieck stellt einen Gruppenführer dar. Es ist aber nicht ausgeschlossen, dass sich Gruppen mit der Zeit ändern und neue Mitglieder gewinnen oder verlieren.
Das Routingverfahren
Die Autoren von Hybrid LANMAR unterteilen das Routing in drei Bereiche: lokale Wegfindung, Finden von Gruppen und Auffinden einzelner Knoten, die nicht in einer Gruppe sind.
Lokale Wegfindung
Für das lokale Routing innerhalb eines bestimmten Bereichs wird das Fisheye Protokoll genutzt. Es begrenzt die Entfernung (Hops) auf einen relativ kleinen festgelegten Wert und ist ein proaktives Verfahren.
Finden von Gruppen
Damit auch außerhalb des lokalen Bereichs Wege gefunden werden können, wird das Verfahren um einen Gruppenführer (=GF) erweitert. Er ist Repräsentant seiner Gruppe und für die Vernetzung mit weiteren Gruppen zuständig. Sobald ein GF bestimmt wurde, fängt dieser an das gesamte Netzwerk über sein Dasein zu informieren. Doch wie wird ein GF bestimmt? Als GF wird der Knoten gewählt, der die meisten benachbarten Knoten in seiner Gruppe besitzt, üblicherweise sollte dies in der Mitte der Gruppe und nicht am Rand der Fall sein.
Finden externer Knoten
Beim klassischen LANMAR Protokoll ist jeder externe Knoten als seine eigene Gruppe definiert. Je mehr externe Knoten es gibt, desto mehr Gruppen existieren. Folglich sinkt die Skalierbarkeit. Hier setzt Hybrid LANMAR an und nutzt dafür ein reaktives Routingverfahren, das nicht ständigen, schlecht skalierbaren, proaktiven Aktualisierungen unterliegt, da es von der Gruppenstruktur getrennt arbeitet.
Ablauf der Wegefindung
Ein jeder Knoten speichert die drei Routingtabellen für lokales Routing, Routing innerhalb der Gruppen (engl.: Landmark Routing Table), Routing für externe Knoten und einen Zwischenspeicher über die Gruppenzugehörigkeit der Zielknoten lokal ab. Der Ablauf der Wegefindung sieht dann wie folgt aus:
- Existiert das Ziel bereits in der Tabelle für lokales Routing, wird nach dieser an den nächsten Knoten Weitergeleitet.
- Wenn das Ziel nicht in der Tabelle für lokales Routing steht, wird nach der Gruppenzugehörigkeit gefragt. Wie das genau passiert erkläre ich später.
- Konnte das Ziel einer Gruppe zugeordnet werden, wird das Paket in Richtung des GF dieser Gruppe weitergeleitet. Ist das Paket in der Zielgruppe angekommen, wird nach der Tabelle für lokales Routing verfahren.
- Wenn das Ziel keiner Gruppe zugeordnet werden konnte, handelt es sich um einen externen Knoten und es wird mit einem reaktiven Verfahren die Wegewahl bestimmt.
Wie wird die Gruppenzugehörigkeit bestimmt? Dazu muss man wissen, dass bei Hybrid LANMAR eine IP-Adresse in zwei Hälften aufgeteilt wird. Die erste Hälfte enthält die (variable) Nummer der zugehörigen Gruppe eines Knotens und die zweite Hälfte dessen eindeutige Kennung/Adresse. Als Gruppennummer wird einfach die Kennung des GF genutzt. Ist ein Knoten nicht Mitglied einer Gruppe, wird seine Gruppennummer auf null gesetzt. Um die Gruppenzugehörigkeit festzustellen wird ein verteiltes System zur Namensauflösung (DNS) mit der Kennung des Zielknotens befragt und als Antwort erhält man eine IP-Adresse mitsamt Gruppennummer und Knotenkennung.
Meiner Meinung nach liegen hier einige Schwachstellen in der Erklärung seitens der Erfinder von Hybrid LANMAR. Wie soll dieses verteilte DNS-System aussehen? Muss jeder x-te Knoten solche Informationen bereitstellen oder wie sieht dies in der Realität aus? Erzeugt ein solches System nicht zusätzliche Bandbreite?
Auch beim Routing zur nächsten Gruppe bleiben noch Fragen offen. Ist ein Paket von einer Gruppe bei der nächsten Gruppe angekommen, so soll nach dem Willen der Autoren nach der Tabelle für lokales Routing die Wegewahl bestimmt werden. Aber was ist wenn es eine große Gruppe ist und die Anzahl der möglichen Hops zu klein gewählt wurde? Hier hätte eine Grafik zur Erklärung vielleicht behilflich sein können.
Anwendungen in der Praxis
Der Entwurf zu Hybrid LANMAR ist vom September 2005 und damit noch sehr neu. Anwendungen in der Praxis wird man schwerlich finden, weshalb ich mich kurz auf die Resultate der Tests aus dem Entwurf beziehen werde.
Glaubt man den Statistiken, ist Hybrid LANMAR eine erfolgreiche Verbesserung des ursprünglichen LANMAR Protokolls. Es sind nur wenige Nachteile zu erkennen. Hybrid LANMAR benötigt etwas mehr Verwaltungsaufwand zur Wegebestimmung. Durch das reaktive Routing steigt außerdem die Verzögerung bis ein Paket übertragen wurde. Die Vorteile überwiegen, denn bei gleichem Durchsatz weist Hybrid LANMAR eine wesentlich höhere Anzahl erfolgreich zugestellter Pakete auf, je mehr externe Knoten es gibt. Das Ziel der Entwickler scheint erfüllt.
Kritik
Ursprünglich hatte ich in meiner Seminararbeit am Ende OLSR und Hybrid LANMAR verglichen. Da hier nur der Teil über Hybrid LANMAR zu finden ist und ich nicht alles neu schreiben wollte, habe ich einen passenden Abschnitt kopiert. Dieser befasst sich mit möglichen Problemen:
Bei Hybrid LANMAR wird es sich negativ auswirken, wenn eine Gruppe ihren GF verliert und dadurch bei allen Knoten der Eintrag aktualisiert werden muss. Während bei OLSR keine Änderungen an den IP-Adressen notwendig waren, baut Hybrid LANMAR auf eine Kombination von Knoten- und Gruppenkennung auf. Bei nicht angepassten Anwendungen kann dies zu Problemen führen, da sich die Adresse durch eine neue Gruppenzuordnung ändert. Auch die Rückgewinnung der Gruppenzugehörigkeit über das verteilte DNS-System lässt noch offene Fragen, die erst noch geklärt werden müssen.
Mehr Infos